Claude Opus 4.7 dans Claude Code : le guide pour ne pas cramer tes tokens
Opus 4.7 change la donne côté coding agentique, mais consomme plus de tokens si tu le pilotes comme Opus 4.6. Niveau d'effort xhigh, adaptive thinking, comportements par défaut — voici comment adapter ton workflow concrètement.
Durée
15 min
Niveau
Intermédiaire
Outils
Claude Code · Claude Opus 4.7
J’ai passé deux jours à migrer mes workflows d’Opus 4.6 vers Opus 4.7 dans Claude Code. Verdict brut : le modèle est meilleur partout, mais si tu gardes exactement tes habitudes de la version précédente, tu vas cramer entre 30 et 60% de tokens en plus pour rien.
Le problème n’est pas le modèle. Le problème c’est qu’Anthropic a changé deux choses qui modifient la consommation : un nouveau tokenizer, et surtout une tendance du modèle à penser davantage aux niveaux d’effort élevés — particulièrement sur les tours tardifs dans les longues sessions interactives.
Ce guide, c’est mes notes de terrain pour adapter ton setup Claude Code sans tout casser. On va voir :
- Pourquoi il faut arrêter de traiter Claude comme un pair-programmer
- Quel niveau d’effort choisir selon le type de tâche (et pourquoi
xhighn’est pas toujours la bonne réponse) - Comment l’adaptive thinking remplace l’ancien budget fixe
- Les trois comportements par défaut qui ont changé et qui vont casser tes prompts existants
1. Arrête le mode pair-programmer, passe en mode délégation
Le premier réflexe avec Opus 4.6 c’était souvent de piloter Claude au tour par tour. Tu lui donnes une tâche floue, il pose une question, tu précises, il bosse un peu, tu corriges, etc. C’était une conversation.
Avec Opus 4.7, cette approche devient coûteuse. Pour une raison simple : à chaque tour utilisateur en session interactive, le modèle raisonne davantage avant de répondre. Plus la session est longue, plus cet overhead s’accumule. Résultat, cinq tours de ping-pong consomment beaucoup plus que sur la version précédente.
La parade est mentale avant d’être technique : traite Claude comme un ingénieur senior à qui tu délègues, pas comme un binôme que tu guides ligne par ligne.
Concrètement, dans mon workflow :
❌ Avant (style 4.6)
> Refactore le service d'auth
(Claude pose 3 questions, je réponds)
> Oui utilise Zod
(Claude commence, je lis, je corrige)
> Non, on garde JWT finalement
✅ Maintenant (style 4.7)
> Refactore src/services/auth.ts pour :
> - Valider les payloads avec Zod (schémas dans src/schemas/)
> - Garder JWT (lib actuelle jsonwebtoken) mais extraire la config dans src/config/jwt.ts
> - Les erreurs de validation doivent renvoyer 400 avec le format { error, details }
> - Critère d'acceptation : les tests dans tests/auth/ doivent tous passer
> - Ne touche pas aux routes, juste le serviceLa règle : intent + contraintes + critères d’acceptation + fichiers concernés, tout en premier tour. Tu donnes moins de tours, tu obtiens une meilleure qualité, tu consommes moins.
Les trois leviers qui m’ont le plus économisé de tokens
Batcher les questions. Si j’ai besoin de clarifier, je liste tout ce dont Claude a besoin dans un seul tour au lieu d’étaler.
Le mode auto (research preview sur Max). Sur les tâches longues où je fais confiance à l’exécution, Shift+Tab pour activer auto mode. Plus de check-in permanent, le modèle avance. Je l’utilise surtout pour les migrations multi-fichiers et les refactos bien spécifiés.
Les notifications. Demande à Claude de jouer un son quand il a fini. Il se crée son propre hook et tu peux partir faire autre chose. Exemple de prompt que j’utilise :
Quand tu as fini cette tâche (ou si tu es bloqué et as besoin de moi),
crée un hook qui joue un son système. Je vais passer sur un autre écran.2. Les niveaux d’effort : lequel choisir vraiment
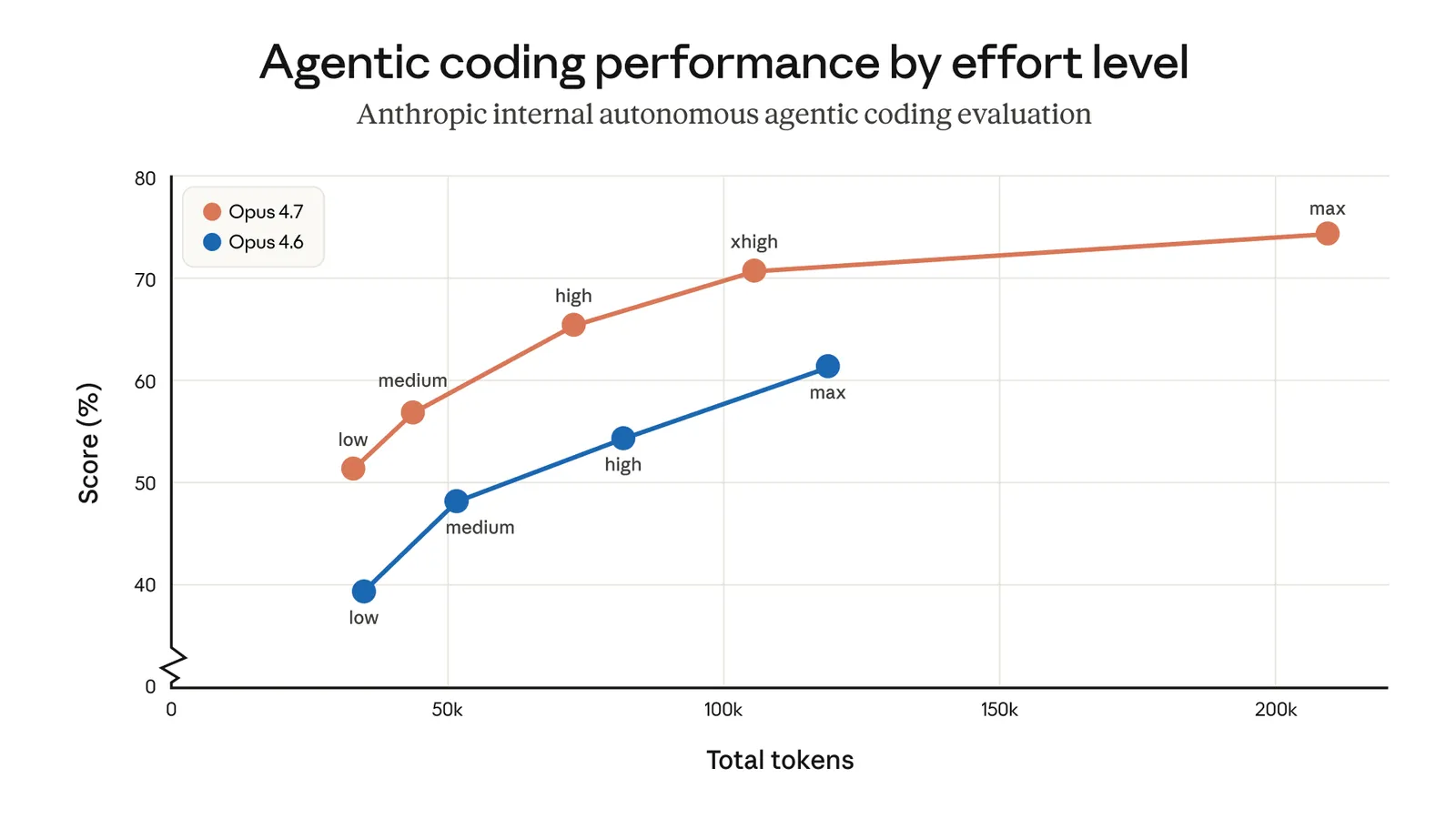
Opus 4.7 introduit un nouveau niveau entre high et max : xhigh. Et c’est désormais le défaut dans Claude Code. Si tu n’avais jamais touché à ton niveau d’effort, tu as été upgradé automatiquement.
Voici ma grille de décision après deux semaines d’utilisation :
| Niveau | Quand je l’utilise | Quand je l’évite |
|---|---|---|
low / medium | Tâches cadrées : renommer des variables, générer un CRUD basique, écrire des tests simples à partir d’un squelette existant | Tout ce qui implique un choix d’architecture |
high | Sessions parallèles (3-4 Claude Code ouverts en même temps), scripts one-shot où la qualité absolue n’est pas critique | Debug complexe, design d’API |
xhigh (défaut) | 80% de mon temps : refacto multi-fichiers, design d’API, migration legacy, code review d’une feature | Les tâches triviales — c’est du gâchis |
max | Quand xhigh a échoué deux fois sur un problème vraiment dur. Bugs de concurrence, algos complexes, évals | Tout le reste — le modèle a tendance à over-thinker |
Le piège à éviter : porter bêtement ton ancien setting 4.6 sur 4.7. Si tu étais en max par défaut sur 4.6, descends à xhigh sur 4.7. Tu perdras très peu en qualité et tu économiseras beaucoup.
Astuce qui change la vie
Tu peux toggler le niveau d’effort pendant la tâche. Tu démarres en xhigh pour cadrer l’architecture, tu passes en medium une fois que Claude exécute du code répétitif sur 15 fichiers, tu remontes si ça coince. Trois secondes de réglage, parfois 40% de tokens économisés sur une session.
3. Adaptive thinking : oublie les budgets fixes
Sur Opus 4.6, tu pouvais allouer un budget de thinking tokens explicite avec Extended Thinking. Sur 4.7, c’est fini. Le modèle décide lui-même, à chaque étape, s’il a besoin de réfléchir ou pas.
En pratique c’est plutôt bien : sur les requêtes simples (« quel est le type de retour de cette fonction ? »), il répond direct. Sur les problèmes durs, il prend le temps. Et il over-think nettement moins que 4.6.
Si tu veux plus de contrôle, prompte explicitement :
✅ Plus de réflexion
> Réfléchis soigneusement et étape par étape avant de répondre.
> Ce problème est plus subtil qu'il n'y paraît.
✅ Moins de réflexion (économie)
> Priorité à la rapidité de réponse plutôt qu'à la réflexion profonde.
> En cas de doute, réponds directement.Le deuxième prompt est précieux sur les sessions où tu fais beaucoup de lookups dans une grosse codebase. Tu sacrifies un peu de précision sur les étapes dures, mais tu divises les tokens par deux sur tout le reste.
4. Les trois changements de comportement qui vont casser tes prompts existants
A. Les réponses sont calibrées à la complexité de la tâche
Opus 4.6 était verbeux par défaut. Opus 4.7 non. Sur un lookup simple, attends-toi à une réponse courte. Sur une analyse ouverte, il prendra la place nécessaire.
Si tu avais un prompt du style « Sois concis » ou « N’ajoute pas de préambule » — tu peux probablement le supprimer, c’est devenu le comportement par défaut.
Si au contraire tu as besoin d’une longueur ou d’un style spécifique, déclare-le explicitement. Et astuce qui marche mieux : donne un exemple positif du ton que tu veux, plutôt que lister les « ne fais pas ». Le modèle copie bien mieux un exemple qu’il n’évite une interdiction.
B. Moins d’appels d’outils, plus de raisonnement interne
Opus 4.7 appelle les outils moins souvent qu’avant. À la place, il raisonne plus. Dans la plupart des cas c’est mieux : moins de lectures de fichiers inutiles, moins de recherches redondantes.
Mais si ton workflow dépend d’outils — par exemple un agent de recherche qui doit agressivement explorer la codebase — il faut lui dire explicitement :
> Avant de répondre, utilise systématiquement l'outil de recherche
> pour vérifier les usages existants dans la codebase. Ne te repose
> pas sur ta connaissance générale du projet.C. Il spawne moins de subagents par défaut
C’est le changement qui m’a le plus surpris. Sur 4.6, Claude avait tendance à déléguer à des subagents dès qu’une tâche paraissait un peu large. Sur 4.7, il est plus économe : souvent il fait le travail directement.
Si ton pattern c’est un agent principal qui fan-out sur des subagents (lecture parallèle de 10 fichiers, exploration de plusieurs pistes en parallèle), il faut désormais le prompter explicitement. Exemple que j’ai ajouté à mon CLAUDE.md :
## Règle subagents
- Ne spawne pas de subagent pour un travail que tu peux faire
directement (ex. refactor d'une fonction que tu as sous les yeux).
- Spawne plusieurs subagents dans le même tour quand tu fan-outes
sur plusieurs items indépendants (analyse de 5 fichiers, évaluation
de 3 pistes d'architecture en parallèle, etc.).Cette règle explicite m’a redonné le comportement que j’avais par défaut sur 4.6, tout en gardant les gains de qualité de 4.7.
5. Par quoi commencer
Si tu veux tester Opus 4.7 honnêtement, voici ma recette :
- Laisse le niveau d’effort sur
xhigh(le défaut) pour la première semaine. Ne le change pas. - Reprends une tâche longue où Opus 4.6 galérait — un debug sur 4-5 fichiers, une code review d’un service entier, une migration legacy. C’est là où 4.7 brille.
- Écris ton premier prompt en mode délégation complète : intent + contraintes + critères d’acceptation + fichiers. Un seul tour. Vois jusqu’où le modèle va sans intervention.
- Observe la consommation de tokens sur le dashboard. Si elle explose, relis la section 1 — probablement tu multiplies les tours utilisateur.
Les gains que j’ai vus personnellement : un debug qui me prenait 3h à l’ancienne (avec 15 allers-retours) résolu en une seule passe de 12 minutes. Un refacto multi-fichiers sur 8 services validé du premier coup. Un code review d’une PR de 400 lignes avec des findings réellement pertinents (pas juste du style).
Le bad : les scripts one-shot où Opus 4.6 en max faisait déjà le job en 30 secondes prennent maintenant 45 secondes sur 4.7 en xhigh pour un résultat équivalent. Sur ces cas, passe en high ou medium.
Ce qu’il faut retenir
Opus 4.7 est clairement plus fort sur les tâches longues et ambiguës. C’est précisément là où la supervision humaine était le goulot d’étranglement : refactos complexes multi-fichiers, debug ambigu, revue de code à l’échelle d’un service, travail agentique en plusieurs étapes.
Mais il faut changer ton interface avec lui. Moins de tours, plus de contexte dès le départ, niveau d’effort ajusté à la tâche, comportements par défaut re-prompter quand nécessaire. Le modèle fait sa part, mais il t’oblige à faire la tienne.
Garde xhigh, écris des prompts complets dès le premier tour, et regarde où le modèle t’emmène sans que tu l’interrompes. C’est le meilleur moyen de voir ce qui a vraiment changé.
Aller plus loin