Claude Opus 4.7 in Claude Code: the guide to not burning your tokens
Opus 4.7 is a leap forward for agentic coding, but it'll eat 30–60% more tokens if you keep driving it like Opus 4.6. Effort levels, adaptive thinking, default behaviors — here's how to actually adapt your workflow.
Duration
15 min
Level
Intermediate
Tools
Claude Code · Claude Opus 4.7
I spent two days migrating my Claude Code workflows from Opus 4.6 to Opus 4.7. Blunt verdict: the model is better across the board, but if you stick to your 4.6 habits you’ll burn 30 to 60% more tokens for no reason.
It’s not the model’s fault. Anthropic shipped two changes that quietly rework token usage: a new tokenizer, and a stronger tendency to think at higher effort levels — especially on later turns in long interactive sessions.
This is my field notes guide to adapting your Claude Code setup without breaking everything. We’ll cover:
- Why you should stop treating Claude like a pair-programmer
- Which effort level to pick depending on the task (and why
xhighisn’t always the answer) - How adaptive thinking replaced the old fixed thinking budget
- The three default behaviors that changed and will break your existing prompts
1. Drop the pair-programmer mode, switch to delegation
With Opus 4.6, the default move was often to drive Claude turn by turn. You’d give a fuzzy task, it asked a question, you clarified, it did a bit of work, you corrected, repeat. It was a conversation.
With Opus 4.7, that approach is expensive. The reason is simple: on every user turn in an interactive session, the model now reasons more before responding. The longer the session, the more that overhead stacks. Five ping-pong turns consume way more tokens than on the previous version.
The fix is mental before it’s technical: treat Claude like a senior engineer you’re delegating to, not a co-pilot you guide line by line.
In practice, in my workflow:
❌ Old (4.6 style)
> Refactor the auth service
(Claude asks 3 questions, I answer)
> Yes use Zod
(Claude starts, I read, I correct)
> Actually keep JWT
✅ Now (4.7 style)
> Refactor src/services/auth.ts to:
> - Validate payloads with Zod (schemas in src/schemas/)
> - Keep JWT (current lib jsonwebtoken) but extract config to src/config/jwt.ts
> - Validation errors should return 400 with format { error, details }
> - Acceptance criteria: all tests in tests/auth/ must pass
> - Don't touch routes, just the serviceThe rule: intent + constraints + acceptance criteria + file paths, all in the first turn. Fewer turns, better quality, cheaper runs.
The three levers that saved me the most tokens
Batch your questions. If I need to clarify, I bundle everything Claude needs in one turn rather than drip-feeding.
Auto mode (research preview on Max). On long tasks where I trust the execution, Shift+Tab toggles auto mode. No more constant check-ins, the model just moves. I mostly use it for multi-file migrations and well-specified refactors.
Notifications. Ask Claude to play a sound when it’s done. It’ll build its own hook and you can walk away. Sample prompt I use:
When you finish this task (or if you're blocked and need me),
create a hook that plays a system sound. I'm switching screens.2. Effort levels: which one to actually pick
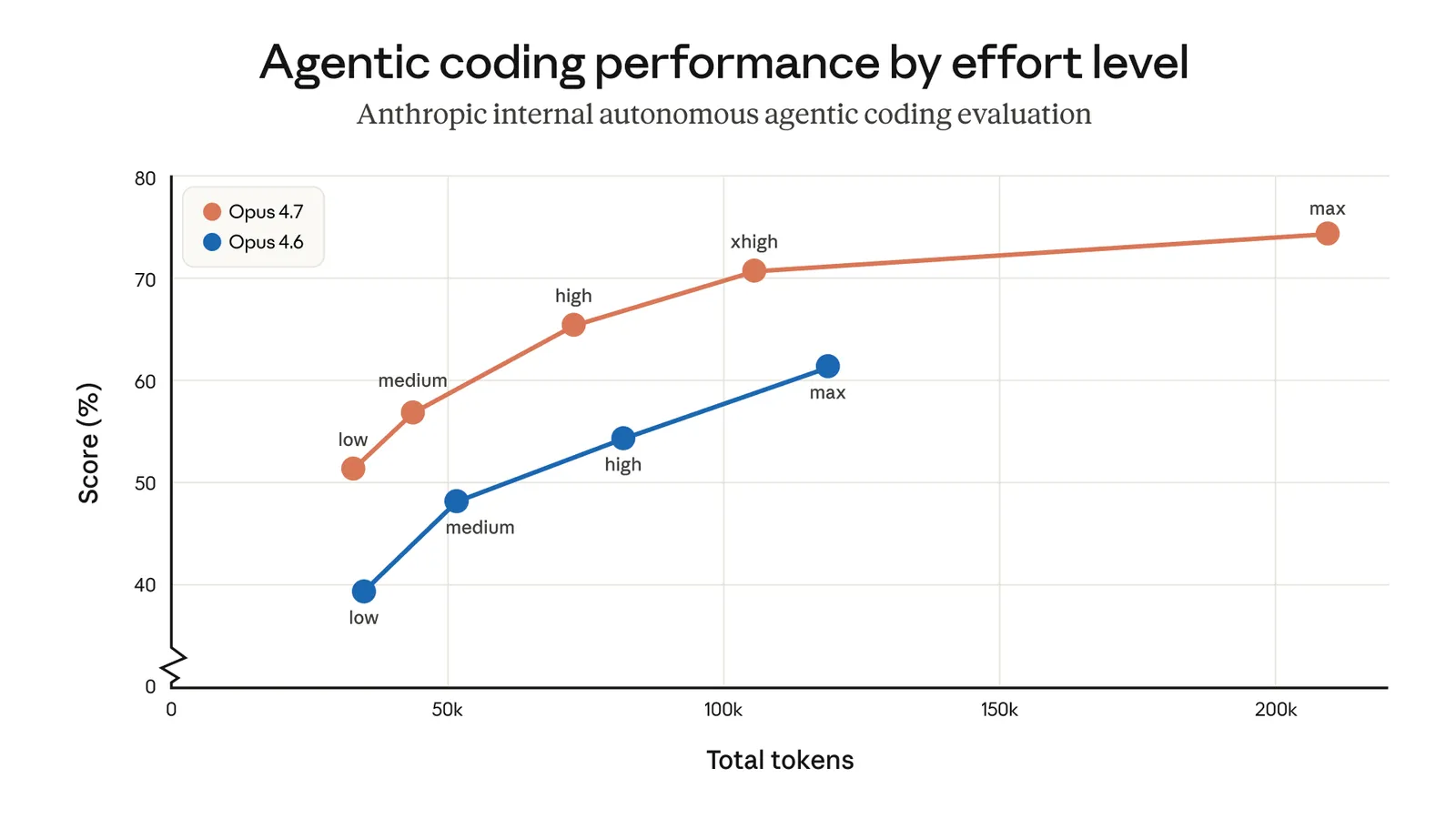
Opus 4.7 adds a new tier between high and max: xhigh. It’s now the default in Claude Code. If you never manually touched your effort level, you’ve been auto-upgraded.
Here’s my decision grid after two weeks of use:
| Level | When I use it | When I skip it |
|---|---|---|
low / medium | Scoped tasks: renaming variables, generating a basic CRUD, writing simple tests from an existing skeleton | Anything involving an architectural choice |
high | Parallel sessions (3–4 Claude Codes open at once), one-shot scripts where absolute quality isn’t critical | Complex debugging, API design |
xhigh (default) | 80% of my time: multi-file refactors, API design, legacy migration, reviewing a feature | Trivial tasks — it’s wasteful |
max | When xhigh has failed twice on a genuinely hard problem. Concurrency bugs, complex algorithms, evals | Everything else — the model tends to overthink |
The trap to avoid: blindly porting your 4.6 setting to 4.7. If you ran 4.6 at max by default, drop to xhigh on 4.7. You’ll lose almost nothing in quality and save a lot.
The tip that changes everything
You can toggle the effort level mid-task. Start in xhigh to nail the architecture, drop to medium once Claude is cranking out repetitive code across 15 files, climb back if it stalls. Three seconds of tweaking sometimes saves 40% of tokens over a session.
3. Adaptive thinking: forget fixed budgets
On Opus 4.6, you could allocate an explicit thinking-token budget with Extended Thinking. On 4.7, it’s gone. The model now decides, step by step, whether it needs to think.
In practice it works well: on simple queries (“what’s the return type of this function?”) it answers instantly. On hard problems, it takes its time. And it overthinks way less than 4.6.
If you want more control, prompt for it explicitly:
✅ More thinking
> Think carefully and step by step before answering.
> This problem is subtler than it looks.
✅ Less thinking (savings)
> Prioritize quick responses over deep thinking.
> When in doubt, answer directly.The second prompt is gold on sessions with lots of lookups in a big codebase. You sacrifice some accuracy on hard steps, but cut tokens in half on everything else.
4. The three default-behavior changes that will break your existing prompts
A. Response length is calibrated to task complexity
Opus 4.6 was verbose by default. Opus 4.7 isn’t. On a simple lookup, expect a short answer. On an open-ended analysis, it takes the room it needs.
If you had a prompt like “Be concise” or “No preamble” — you can probably drop it, that’s the default now.
If on the other hand you need a specific length or style, state it explicitly. And the trick that works better: give a positive example of the voice you want, rather than listing “don’t do this”. The model copies an example far better than it avoids a prohibition.
B. Fewer tool calls, more internal reasoning
Opus 4.7 calls tools less often than before. It reasons more instead. In most cases that’s a win: fewer pointless file reads, fewer redundant searches.
But if your workflow depends on tools — say, a research agent that should aggressively explore the codebase — you need to say so explicitly:
> Before responding, always use the search tool to verify existing
> usages in the codebase. Don't rely on your general knowledge
> of the project.C. It spawns fewer subagents by default
This is the change that surprised me most. On 4.6, Claude would delegate to subagents fairly readily on any slightly broad task. On 4.7, it’s more frugal: often it just does the work itself.
If your pattern is a main agent fanning out to subagents (parallel read of 10 files, exploring multiple leads in parallel), you now have to prompt for it explicitly. Here’s what I added to my CLAUDE.md:
## Subagent rule
- Do not spawn a subagent for work you can do directly
(e.g. refactoring a function you're already looking at).
- Spawn multiple subagents in the same turn when fanning out
across independent items (analyzing 5 files, evaluating
3 architecture leads in parallel, etc.).That explicit rule restored the default behavior I had on 4.6, while keeping 4.7’s quality gains.
5. Where to start
If you want to test Opus 4.7 honestly, here’s my recipe:
- Leave effort at
xhigh(the default) for the first week. Don’t touch it. - Pick up a long task where Opus 4.6 struggled — a 4–5 file debug, a service-wide code review, a legacy migration. That’s where 4.7 shines.
- Write your first prompt in full delegation mode: intent + constraints + acceptance criteria + files. One turn. See how far the model goes without your input.
- Watch the token usage on the dashboard. If it explodes, revisit section 1 — chances are you’re multiplying user turns.
The wins I’ve personally seen: a debug that used to take me 3 hours old-school (with 15 back-and-forths) solved in a single 12-minute pass. A multi-file refactor across 8 services approved on the first try. A code review on a 400-line PR with genuinely relevant findings (not just style nits).
The downside: one-shot scripts where Opus 4.6 at max already did the job in 30 seconds now take 45 seconds on 4.7 at xhigh for equivalent output. For those cases, drop to high or medium.
Key takeaways
Opus 4.7 is clearly stronger on long, ambiguous tasks. That’s precisely where human supervision used to be the bottleneck: complex multi-file refactors, ambiguous debugging, service-wide code review, multi-step agentic work.
But you have to change your interface with it. Fewer turns, more context upfront, effort level tuned to the task, default behaviors re-prompted when needed. The model does its part, but it forces you to do yours.
Keep xhigh, write complete prompts in the first turn, and watch how far the model takes you without interruption. That’s the best way to see what actually changed.
Keep learning