Blog / · 6 min de lecture
Leçons de Claude Code : le Prompt Caching est Tout
Thariq Shihipar (Anthropic) partage les leçons d'optimisation du prompt caching à l'échelle. Ordre du prompt, messages vs system, compaction cache-safe — ce qui rend Claude Code viable.

« Cache Rules Everything Around Me » — en ingénierie comme pour les agents IA. Les produits agentiques longue durée comme Claude Code ne sont viables que grâce au prompt caching, qui réutilise le calcul des tours précédents et réduit drastiquement latence et coût.
Thariq Shihipar (équipe Claude Code chez Anthropic) a partagé les leçons tirées de l’optimisation du prompt caching à l’échelle. Chez Claude Code, tout le harness est construit autour : un bon taux de cache hit diminue les coûts et permet des rate limits plus généreux. Ils alertent sur le taux de cache hit et déclarent des SEV si il est trop bas.
Voici les leçons — souvent contre-intuitives — qu’ils ont apprises.
Structurer son prompt pour le cache
Le prompt caching fonctionne par prefix matching : l’API met en cache tout le début de la requête jusqu’à chaque point de rupture cache_control. L’ordre des éléments compte énormément — il faut maximiser le préfixe partagé entre les requêtes.
La règle : contenu statique d’abord, dynamique à la fin. Pour Claude Code :
- Instructions système & Tools (cache global)
- CLAUDE.md & Memory (cache par projet)
- Contexte de session (env, MCP, style de sortie) — cache par session
- Messages (conversation) — croît à chaque tour
Cela maximise le nombre de sessions qui partagent des cache hits.
Mais c’est fragile. Exemples de cas où ils ont cassé cet ordre : timestamp détaillé dans le prompt système, ordre des tools non déterministe, mise à jour des paramètres d’un tool (ex. quels agents peut appeler AgentTool), etc.
Passer les mises à jour via les messages
Quand une info du prompt devient obsolète (heure, fichier modifié par l’utilisateur), la tentation est de modifier le prompt. Ça invalide le cache et peut coûter cher.
Mieux : passer l’info dans les messages du tour suivant. Chez Claude Code, ils ajoutent une balise <system-reminder> dans le prochain message utilisateur ou résultat de tool avec l’info mise à jour (ex. « c’est maintenant mercredi »), ce qui préserve le cache.
Ne pas changer de modèle en cours de session
Les caches de prompt sont uniques par modèle. La logique peut devenir contre-intuitive.
Si tu es à 100k tokens avec Opus et tu veux poser une question simple, passer à Haiku serait en fait plus cher que de laisser Opus répondre — il faudrait reconstruire tout le cache pour Haiku.
Pour changer de modèle, la bonne approche : les subagents. Opus prépare un message de « handoff » vers un autre modèle pour la tâche à déléguer. C’est ce qu’ils font avec les agents Explore dans Claude Code, qui utilisent Haiku.
Ne jamais ajouter ou retirer de tools en cours de session
Changer l’ensemble des tools au milieu d’une conversation est l’une des causes les plus fréquentes de cache miss. L’idée semble logique : ne donner que les tools nécessaires. Mais les tools font partie du préfixe caché — ajouter ou retirer un tool invalide le cache pour toute la conversation.
Plan Mode : concevoir autour du cache
Le Plan Mode illustre bien la conception sous contrainte de cache. L’approche naïve : quand l’utilisateur entre en plan mode, remplacer les tools par des tools read-only. Ça casserait le cache.
Leur solution : garder tous les tools à tout moment, et utiliser EnterPlanMode et ExitPlanMode comme tools. Quand l’utilisateur active le plan mode, l’agent reçoit un message système expliquant qu’il est en plan mode (explorer le codebase, ne pas éditer, appeler ExitPlanMode quand le plan est prêt). Les définitions de tools ne changent jamais.
Bonus : comme EnterPlanMode est un tool que le modèle peut appeler lui-même, il peut entrer en plan mode de façon autonome quand il détecte un problème complexe — sans casser le cache.
Tool Search : différer plutôt que retirer
Même principe pour la recherche de tools. Claude Code peut charger des dizaines de tools MCP ; les inclure tous dans chaque requête serait coûteux. Les retirer en cours de conversation casserait le cache.
Leur solution : defer_loading. Au lieu de retirer des tools, ils envoient des stubs légers — juste le nom du tool avec defer_loading: true — que le modèle peut « découvrir » via un tool ToolSearch quand nécessaire. Les schémas complets ne sont chargés que quand le modèle les sélectionne. Le préfixe caché reste stable : mêmes stubs, même ordre.
L’API Anthropic expose un tool search pour simplifier ça.
Compaction : fork du contexte
La compaction intervient quand le context window est plein : on résume la conversation et on continue avec ce résumé.
Le piège : la compaction a beaucoup d’edge cases avec le prompt caching. Si on envoie toute la conversation à un modèle pour générer le résumé via un appel API séparé avec un autre system prompt et sans tools (implémentation naïve), le préfixe caché de la conversation principale ne matche pas du tout. Tu paies le prix plein pour tous les tokens d’entrée — coût drastique.
La solution : Cache-Safe Forking
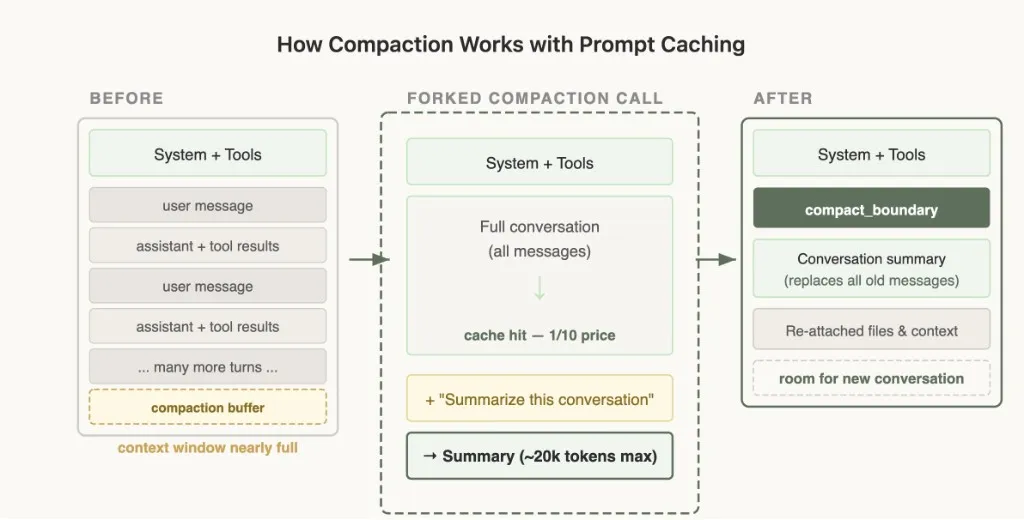
Quand ils font la compaction, ils utilisent exactement le même system prompt, contexte utilisateur, contexte système et définitions de tools que la conversation parente. Ils préfixent les messages de la conversation parente, puis ajoutent le prompt de compaction comme nouveau message utilisateur à la fin.
Du point de vue de l’API, cette requête ressemble presque à la dernière requête du parent — même préfixe, mêmes tools, même historique — donc le préfixe caché est réutilisé. Les seuls nouveaux tokens sont le prompt de compaction lui-même. Cache hit — ~1/10 du prix.
Il faut toutefois réserver un « compaction buffer » pour avoir assez de place dans le context window pour le message de compaction et les tokens de sortie du résumé.
La bonne nouvelle : Anthropic a intégré la compaction directement dans l’API, basée sur ces apprentissages. Tu peux appliquer ces patterns sans réinventer la roue.
Synthèse des leçons
-
Le prompt caching = prefix match. Tout changement dans le préfixe invalide tout ce qui suit. Conçois tout ton système autour de cette contrainte. Bon ordre = la plupart du cache fonctionne gratuitement.
-
Messages plutôt que modifications du system prompt. Pour le plan mode, la date, etc. — insère ces infos dans les messages pendant la conversation.
-
Ne change pas tools ou modèles en cours de conversation. Utilise des tools pour modéliser les transitions d’état (Plan Mode) plutôt que de modifier l’ensemble des tools. Diffère le chargement des tools au lieu de les retirer.
-
Surveille ton cache hit rate comme ton uptime. Ils alertent sur les cache breaks et les traitent comme des incidents. Quelques points de pourcentage de cache miss peuvent dramatiquement impacter coût et latence.
-
Les opérations de fork doivent partager le préfixe du parent. Compaction, summarization, exécution de skill — utilise des paramètres cache-safe identiques pour réutiliser le préfixe du parent.
Claude Code est construit autour du prompt caching depuis le jour un. Si tu construis un agent, tu devrais faire pareil.
Source : Thariq (@trq212) sur X — voir aussi l’article de R. Lance Martin sur le prompt caching et le lancement de l’auto-caching.
Continuer la lecture