Blog / · 6 min read
Lessons from Building Claude Code: Prompt Caching Is Everything
Thariq Shihipar (Anthropic) shares lessons from optimizing prompt caching at scale. Prompt ordering, messages vs system, cache-safe compaction — what makes Claude Code viable.

“Cache Rules Everything Around Me” — in engineering as in AI agents. Long-running agentic products like Claude Code are only viable thanks to prompt caching, which reuses computation from previous roundtrips and drastically reduces latency and cost.
Thariq Shihipar (Claude Code team at Anthropic) shared the lessons learned from optimizing prompt caching at scale. At Claude Code, the entire harness is built around it: a good cache hit rate lowers costs and enables more generous rate limits. They run alerts on cache hit rate and declare SEVs when it’s too low.
Here are the lessons — often counterintuitive — they’ve learned.
Lay Out Your Prompt for Caching
Prompt caching works by prefix matching: the API caches everything from the start of the request up to each cache_control breakpoint. The order of elements matters enormously — you want as many requests as possible to share a prefix.
The rule: static content first, dynamic content last. For Claude Code:
- System instructions & Tools (globally cached)
- CLAUDE.md & Memory (cached per project)
- Session context (env, MCP, output style) — cached per session
- Messages (conversation) — grows each turn
This maximizes how many sessions share cache hits.
But it’s surprisingly fragile. Examples of when they’ve broken this ordering: putting a detailed timestamp in the static system prompt, shuffling tool definitions non-deterministically, updating tool parameters (e.g. which agents AgentTool can call), etc.
Use Messages for Updates
When information in your prompt becomes stale (time, user-edited file), the temptation is to update the prompt. That invalidates the cache and can get expensive.
Better: pass the info in the messages of the next turn. At Claude Code, they add a <system-reminder> tag in the next user message or tool result with the updated info (e.g. “it is now Wednesday”), which preserves the cache.
Don’t Change Models Mid-Session
Prompt caches are unique per model. The math can get counterintuitive.
If you’re 100k tokens into a conversation with Opus and want to ask a simple question, switching to Haiku would actually be more expensive than having Opus answer — you’d need to rebuild the entire cache for Haiku.
To switch models, the right approach: subagents. Opus prepares a “handoff” message to another model for the task to delegate. That’s what they do with the Explore agents in Claude Code, which use Haiku.
Never Add or Remove Tools Mid-Session
Changing the tool set mid-conversation is one of the most common ways to break the cache. The idea seems logical: only give the model the tools it needs. But tools are part of the cached prefix — adding or removing a tool invalidates the cache for the entire conversation.
Plan Mode: Design Around the Cache
Plan Mode is a great example of designing features around caching constraints. The naive approach: when the user enters plan mode, swap tools for read-only only. That would break the cache.
Their solution: keep all tools at all times, and use EnterPlanMode and ExitPlanMode as tools themselves. When the user toggles plan mode, the agent gets a system message explaining it’s in plan mode (explore the codebase, don’t edit files, call ExitPlanMode when the plan is complete). Tool definitions never change.
Bonus: because EnterPlanMode is a tool the model can call itself, it can autonomously enter plan mode when it detects a hard problem — without breaking the cache.
Tool Search: Defer Instead of Remove
Same principle for tool search. Claude Code can have dozens of MCP tools loaded; including them all in every request would be expensive. Removing them mid-conversation would break the cache.
Their solution: defer_loading. Instead of removing tools, they send lightweight stubs — just the tool name with defer_loading: true — that the model can “discover” via a ToolSearch tool when needed. Full tool schemas are only loaded when the model selects them. The cached prefix stays stable: same stubs, same order.
The Anthropic API exposes a tool search to simplify this.
Forking Context — Compaction
Compaction is what happens when the context window runs out: you summarize the conversation and continue with that summary.
The catch: compaction has many edge cases with prompt caching. If you send the full conversation to a model for summarization via a separate API call with a different system prompt and no tools (naive implementation), the cached prefix from the main conversation doesn’t match at all. You pay full price for all input tokens — drastically increasing cost.
The Solution: Cache-Safe Forking
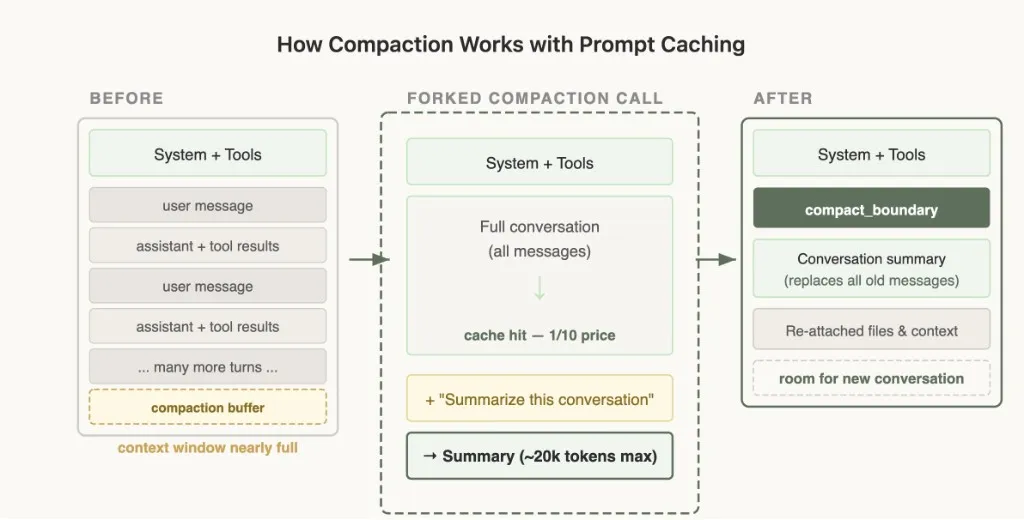
When they run compaction, they use the exact same system prompt, user context, system context, and tool definitions as the parent conversation. They prepend the parent’s conversation messages, then append the compaction prompt as a new user message at the end.
From the API’s perspective, this request looks nearly identical to the parent’s last request — same prefix, same tools, same history — so the cached prefix is reused. The only new tokens are the compaction prompt itself. Cache hit — ~1/10 the price.
You do need to reserve a “compaction buffer” so there’s enough room in the context window for the compaction message and summary output tokens.
The good news: Anthropic built compaction directly into the API based on these learnings. You can apply these patterns without reinventing the wheel.
Lessons Learned
-
Prompt caching = prefix match. Any change in the prefix invalidates everything after it. Design your entire system around this constraint. Get the ordering right and most of the caching works for free.
-
Use messages instead of system prompt changes. For plan mode, date, etc. — insert this info into messages during the conversation.
-
Don’t change tools or models mid-conversation. Use tools to model state transitions (Plan Mode) rather than changing the tool set. Defer tool loading instead of removing tools.
-
Monitor your cache hit rate like uptime. They alert on cache breaks and treat them as incidents. A few percentage points of cache miss can dramatically affect cost and latency.
-
Fork operations must share the parent’s prefix. Compaction, summarization, skill execution — use identical cache-safe parameters to reuse the parent’s prefix.
Claude Code was built around prompt caching from day one. If you’re building an agent, you should do the same.
Source: Thariq (@trq212) on X — see also Anthropic’s prompt caching article and the auto-caching launch.
Keep reading